The Illustrated DeepSeek-R1
A recipe for reasoning LLMs
Jay Alammar Jan 28, 2025
[초안 게시물, 업데이트가 있을 예정입니다. 제안이나 피드백이 있으면 여기나 Bluesky 또는 X/Twitter에 알려주세요.]

DeepSeek-R1은 AI 진전의 꾸준한 드럼롤에서 가장 최근에 울려 퍼지는 비트입니다. ML R&D 커뮤니티에 있어서는 다음과 같은 이유로 주요 릴리스입니다.
1. 더 작고 정제된 버전이 있는 개방형 가중치 모델이며
2. OpenAI O1과 같은 추론 모델을 재생성하는 훈련 방법을 공유하고 반영합니다.
이 게시물에서는 어떻게 만들어졌는지 살펴보겠습니다.
내용:
- 요약: LLM 훈련 방법
- DeepSeek-R1 훈련 레시피
- 1- 추론 SFT 데이터의 긴 체인
- 2- 중간 고품질 추론 LLM(하지만 추론이 아닌 작업에서는 더 나쁨).
- 3- 대규모 강화 학습(RL)을 사용한 추론 모델 생성
- 3.1- 대규모 추론 지향 강화 학습(R1-Zero)
- 3.2- 중간 추론 모델을 사용한 SFT 추론 데이터 생성
- 3.3- 일반 RL 훈련 단계
- 아키텍처
이러한 모델의 작동 방식을 이해하는 데 필요한 기본 지식의 대부분은 저희 책인 Hands-On Large Language Models에서 찾을 수 있습니다.
책의 공식 웹사이트입니다. Amazon에서 책을 주문할 수 있습니다. 모든 코드는 GitHub에 업로드되었습니다.
요약: LLM의 훈련 방법
대부분의 기존 LLM과 마찬가지로 DeepSeek-R1은 한 번에 하나의 토큰을 생성하지만 사고의 사슬을 설명하는 사고 토큰을 생성하는 프로세스를 통해 문제를 처리하는 데 더 많은 시간을 할애할 수 있기 때문에 수학 및 추론 문제를 해결하는 데 뛰어납니다.

다음 그림은 저희 책의 12장에서 발췌한 것으로, 3단계에 걸쳐 고품질 LLM을 만드는 일반적인 레시피를 보여줍니다.

1) 방대한 양의 웹 데이터를 사용하여 다음 단어를 예측하도록 모델을 훈련하는 언어 모델링 단계. 이 단계는 기본 모델을 만듭니다.
2) 지시를 따르고 질문에 답하는 데 모델을 더 유용하게 만드는 감독 미세 조정 단계. 이 단계는 지시 조정 모델 또는 감독 미세 조정/SFT 모델을 만듭니다.
3) 마지막으로 선호도 조정 단계로 동작을 더욱 다듬고 인간의 선호도에 맞춰 최종 선호도 조정 LLM을 만들어 플레이그라운드와 앱에서 상호 작용합니다.
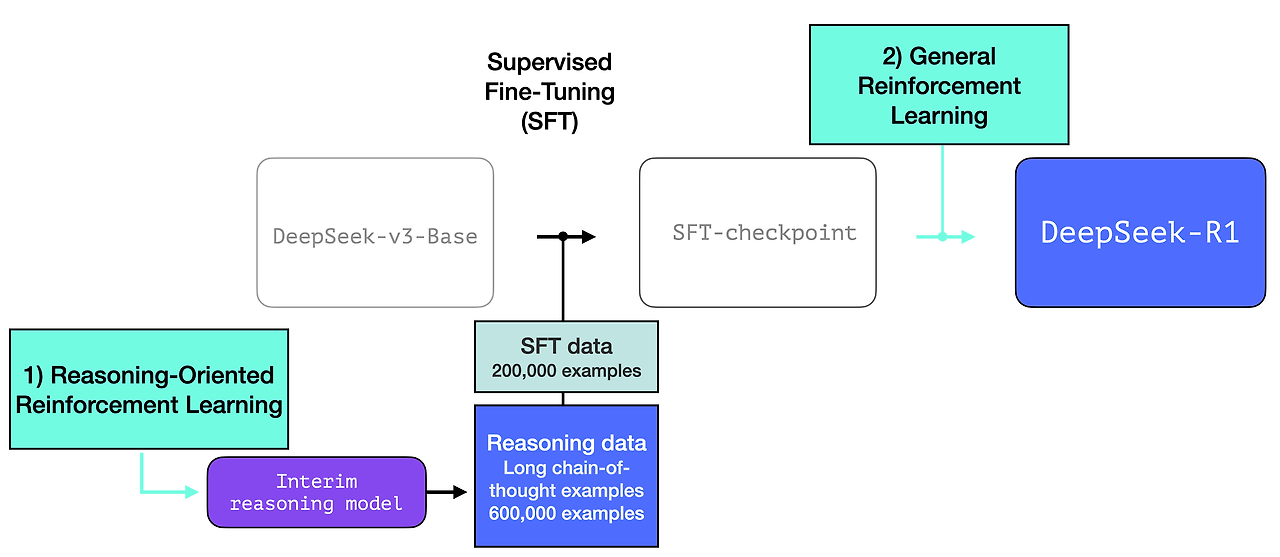
DeepSeek-R1 훈련 레시피
DeepSeek-R1은 이 일반적인 레시피를 따릅니다. 첫 번째 단계의 세부 정보는 DeepSeek-V3 모델에 대한 이전 논문에서 가져왔습니다. R1은 이전 논문의 기본 모델(최종 DeepSeek-v3 모델이 아님)을 사용하고 여전히 SFT 및 선호도 튜닝 단계를 거치지만, 이를 수행하는 방법에 대한 세부 사항이 다릅니다.

R1 생성 프로세스에서 강조해야 할 세 가지 특별한 사항이 있습니다.
1- 추론 SFT 데이터의 긴 사슬
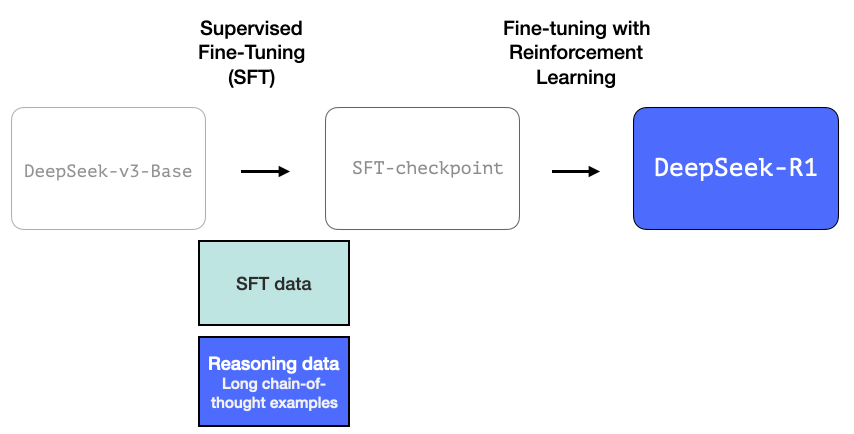
이것은 많은 수의 긴 사고 사슬 추론 사례(600,000개)입니다. 이것들은 구하기 매우 어렵고 이 규모에서 인간에게 레이블을 지정하는 데 매우 비쌉니다. 이것이 이를 만드는 프로세스가 강조해야 할 두 번째 특별한 사항인 이유입니다.
2- 중간 고품질 추론 LLM(하지만 추론이 아닌 작업에서는 더 나쁨).
이 데이터는 추론을 전문으로 하는 이름 없는 형제인 R1의 전신에 의해 생성됩니다. 이 형제는 R1-Zero라는 세 번째 모델에서 영감을 받았습니다(곧 설명하겠습니다). 중요한 이유는 사용하기 좋은 LLM이기 때문이 아니라, 대규모 강화 학습과 함께 레이블이 지정된 데이터가 거의 필요하지 않아 추론 문제를 해결하는 데 뛰어난 모델이 만들어졌기 때문입니다.
이 이름이 지정되지 않은 전문가 추론 모델의 출력은 사용자가 LLM에서 기대하는 수준으로 다른 비추론 작업을 수행할 수 있는 보다 일반적인 모델을 학습하는 데 사용할 수 있습니다.
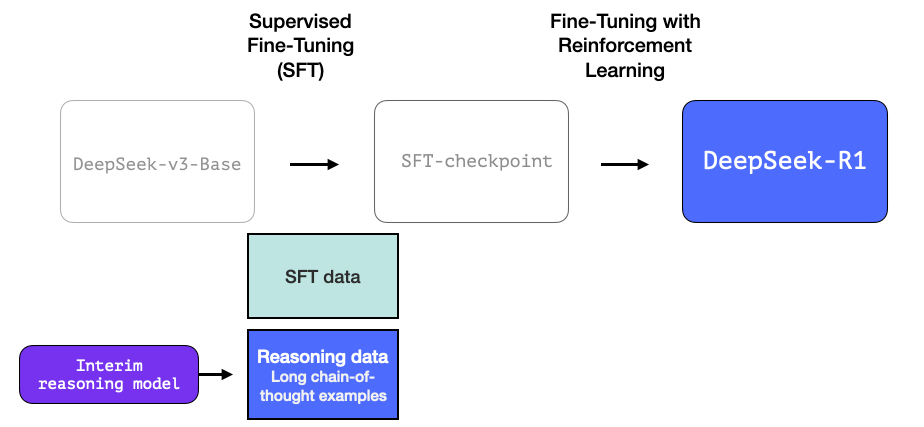
3- 대규모 강화 학습(RL)을 사용하여 추론 모델 만들기
이것은 두 단계로 진행됩니다.

3.1 대규모 추론 지향 강화 학습(R1-Zero)
여기서 RL은 중간 추론 모델을 만드는 데 사용됩니다. 그런 다음 이 모델을 사용하여 SFT 추론 예제를 생성합니다. 하지만 이 모델을 만드는 것이 가능한 이유는 DeepSeek-R1-Zero라는 이전 모델을 만든 이전 실험 때문입니다.

R1-Zero는 레이블이 지정된 SFT 학습 세트 없이도 추론 작업에서 탁월할 수 있기 때문에 특별합니다. 그 훈련은 사전 훈련된 기본 모델에서 RL 훈련 프로세스(SFT 단계 없음)를 거쳐 직접 진행됩니다. 이 과정은 o1과 경쟁할 만큼 잘 진행됩니다.

이는 데이터가 항상 ML 모델 역량의 연료였기 때문에 중요합니다. 이 모델은 어떻게 그 역사에서 벗어날 수 있을까요? 이는 두 가지를 시사합니다.
1- 최신 기본 모델은 품질과 역량의 특정 한계를 넘어섰습니다(이 기본 모델은 14조 8,000억 개의 고품질 토큰에서 훈련되었습니다).
2- 일반적인 채팅이나 쓰기 요청과 달리 추론 문제는 자동으로 검증되거나 레이블이 지정될 수 있습니다. 예를 들어 설명해 보겠습니다. 이는 이 RL 훈련 단계의 일부인 프롬프트/질문이 될 수 있습니다.
숫자 목록을 가져와 정렬된 순서로 반환하지만 시작 부분에 42를 더하는 파이썬 코드를 작성하세요.
이와 같은 질문은 자동 검증의 여러 가지 방법에 적합합니다. 학습 중인 모델에 이것을 제시하고 완성을 생성한다고 가정해 보겠습니다.
- 소프트웨어 린터는 완성이 적절한 파이썬 코드인지 확인할 수 있습니다.
- 파이썬 코드를 실행하여 실행되는지 확인할 수 있습니다.
- 다른 최신 코딩 LLM은 원하는 동작을 확인하기 위해 단위 테스트를 만들 수 있습니다(추론 전문가가 아니어도).
- 한 단계 더 나아가 실행 시간을 측정하고 학습 프로세스가 다른 솔루션보다 성능이 더 좋은 솔루션을 선호하도록 할 수 있습니다. 문제를 해결하는 올바른 파이썬 프로그램일지라도 말입니다.
학습 단계에서 이와 같은 질문을 모델에 제시하고 여러 가지 가능한 솔루션을 생성할 수 있습니다.

사람의 개입 없이도 자동으로 확인하여 첫 번째 완성본이 코드가 아님을 확인할 수 있습니다. 두 번째는 실제로 파이썬 코드이지만 문제를 해결하지 못합니다. 세 번째는 가능한 해결책이지만 단위 테스트에 실패하고 네 번째는 올바른 해결책입니다.

이것들은 모두 모델을 개선하는 데 직접 사용할 수 있는 신호입니다. 물론 이것은 많은 예제(미니 배치)와 연속적인 학습 단계에 걸쳐 수행됩니다.

이러한 보상 신호와 모델 업데이트는 논문의 그림 2에서 볼 수 있듯이 모델이 RL 학습 프로세스에서 작업을 계속 개선하는 방법입니다.

이 기능의 개선과 일치하는 것은 생성된 응답의 길이이며, 여기서 모델은 문제를 처리하기 위해 더 많은 사고 토큰을 생성합니다.
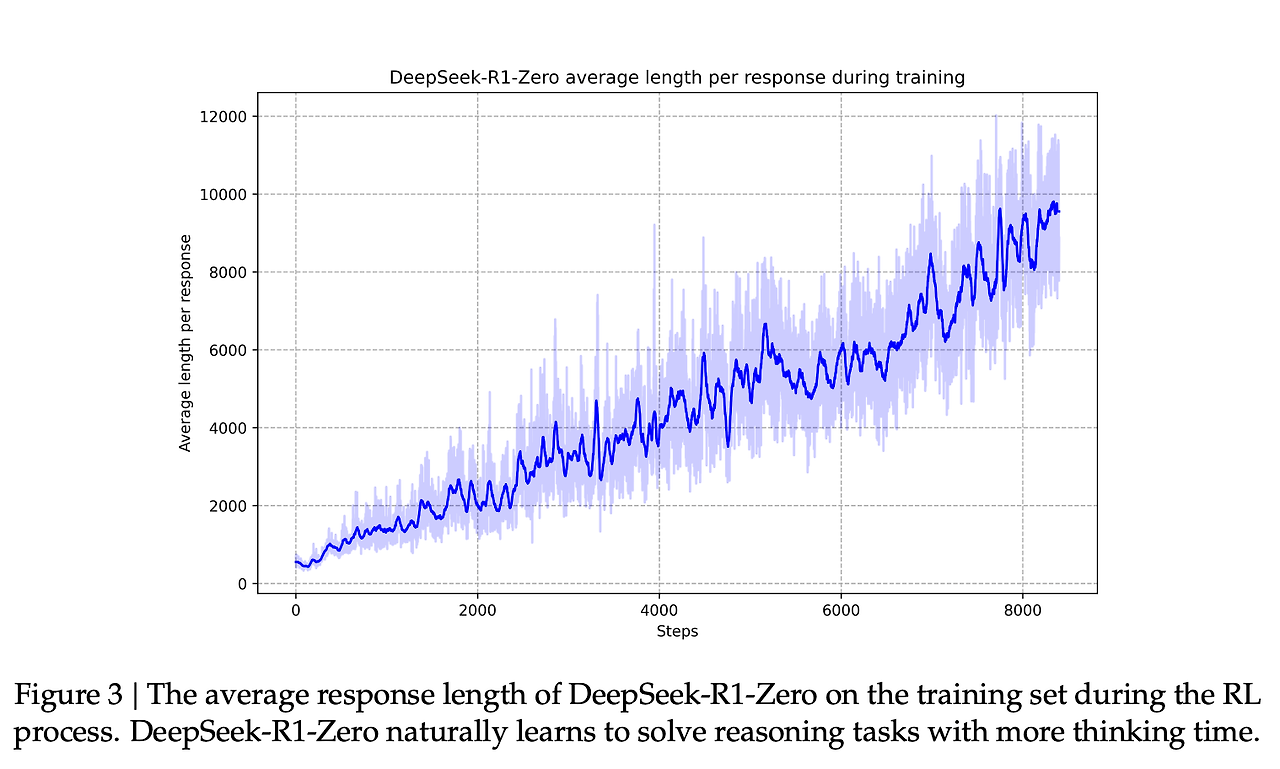
이 프로세스는 유용하지만 R1-Zero 모델은 이러한 추론 문제에서 높은 점수를 받았음에도 불구하고 원하는 것보다 덜 사용 가능하게 만드는 다른 문제에 직면합니다.
DeepSeek-R1-Zero는 강력한 추론 기능을 보여주고 예상치 못한 강력한 추론 행동을 자율적으로 개발하지만 여러 가지 문제에 직면합니다. 예를 들어 DeepSeek-R1-Zero는 가독성 저하 및 언어 혼합과 같은 문제에 어려움을 겪습니다.
R1은 더 사용 가능한 모델이 되어야 합니다. 따라서 RL 프로세스에 전적으로 의존하는 대신 이 섹션의 앞부분에서 언급한 것처럼 두 곳에서 사용됩니다.
1- SFT 데이터 포인트를 생성하기 위한 중간 추론 모델 생성
2- 추론 및 비추론 문제를 개선하기 위한 R1 모델 학습(다른 유형의 검증자 사용)
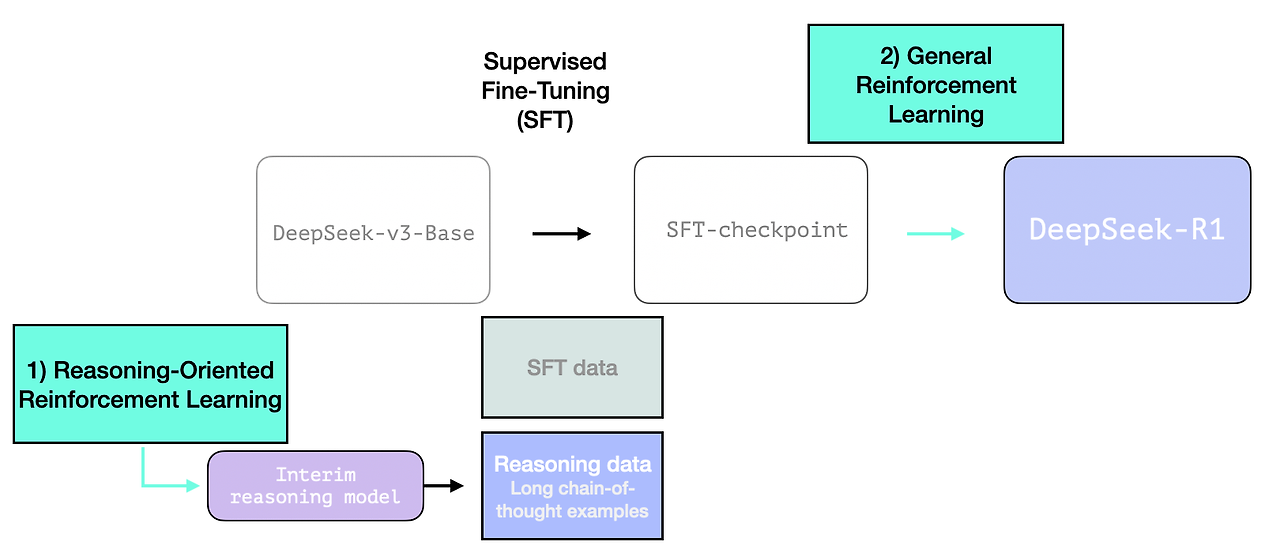
3.2 중간 추론 모델로 SFT 추론 데이터 생성
중간 추론 모델을 보다 유용하게 만들기 위해 수천 개의 추론 문제 사례(일부는 R1-Zero에서 생성 및 필터링)에 대한 지도 미세 조정(SFT) 학습 단계를 거칩니다. 이 논문에서는 이를 "콜드 스타트 데이터"라고 합니다.
2.3.1. 콜드 스타트
DeepSeek-R1-Zero와 달리 기본 모델에서 RL 학습의 초기 불안정한 콜드 스타트 단계를 방지하기 위해 DeepSeek-R1의 경우 소량의 긴 CoT 데이터를 구성하고 수집하여 초기 RL 액터로서 모델을 미세 조정합니다. 이러한 데이터를 수집하기 위해 우리는 몇 가지 접근 방식을 탐구했습니다. 긴 CoT를 예로 들어 few-shot prompting을 사용하고, 모델에 직접 prompting하여 반영 및 검증을 통해 자세한 답변을 생성하고, DeepSeek-R1-Zero 출력을 읽을 수 있는 형식으로 수집하고, 인간 주석자가 후처리를 통해 결과를 정제했습니다.

하지만 잠깐만요, 이 데이터가 있다면 왜 RL 프로세스에 의존하는 걸까요? 데이터의 규모 때문입니다. 이 데이터 세트는 5,000개의 예제일 수 있지만(소싱 가능), R1을 훈련하려면 600,000개의 예제가 필요했습니다. 이 중간 모델은 그 격차를 메우고 매우 귀중한 데이터를 합성적으로 생성할 수 있도록 합니다.
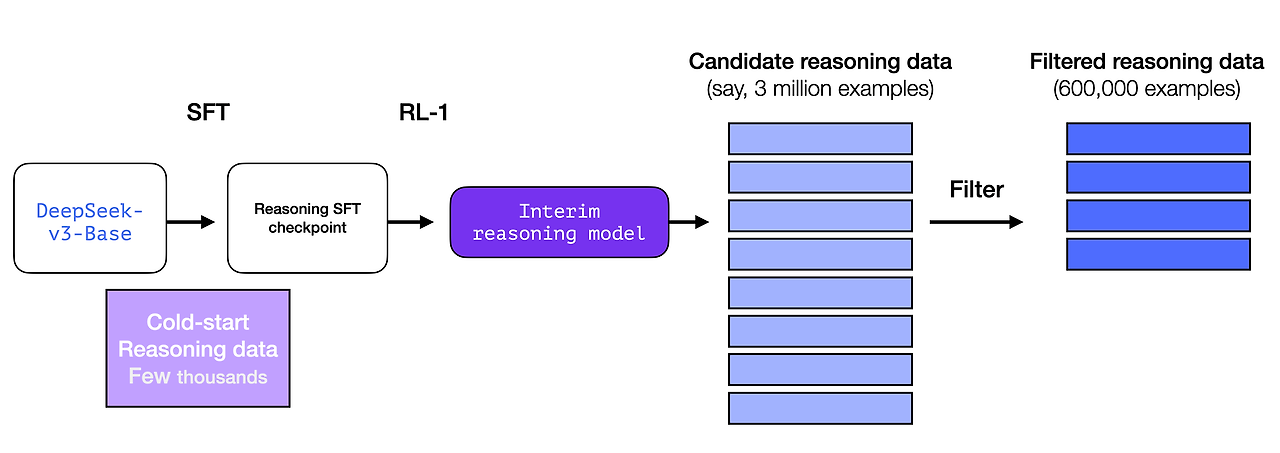
Supervised Fine-Tuning(SFT) 개념이 생소하다면, 이는 신속하고 정확한 완성의 형태로 모델에 훈련 예제를 제공하는 프로세스입니다. 12장의 이 그림은 몇 가지 SFT 훈련 사례를 보여줍니다.

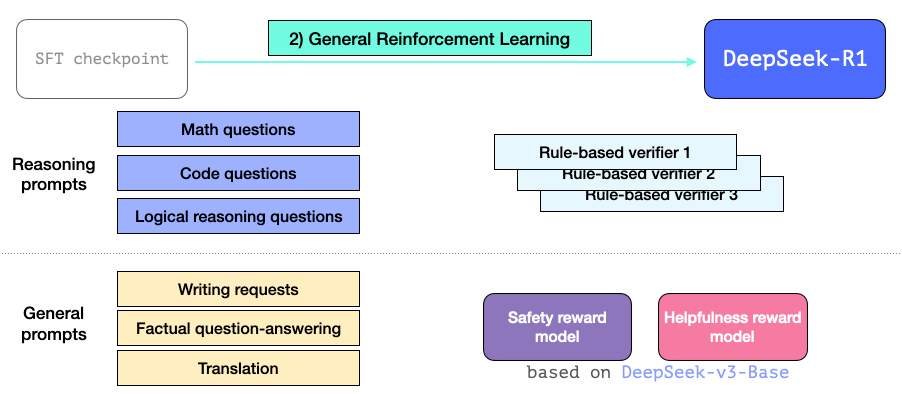
3.3 일반 RL 훈련 단계
이를 통해 R1은 추론 및 기타 비추론 작업에서 탁월해질 수 있습니다. 이 프로세스는 이전에 본 RL 프로세스와 유사합니다. 하지만 비추론 애플리케이션으로 확장되므로 이러한 애플리케이션에 속하는 프롬프트에 대해 유용성 및 안전 보상 모델(라마 모델과 다름없음)을 활용합니다.
아키텍처
GPT2 및 GPT 3의 시작부터의 이전 모델과 마찬가지로 DeepSeek-R1은 Transformer 디코더 블록의 스택입니다. 61개로 구성되어 있습니다. 처음 세 개는 밀도가 높지만 나머지는 전문가 혼합 레이어입니다(공동 저자인 Maarten의 놀라운 소개 가이드를 여기에서 확인하세요: 전문가 혼합(MoE)에 대한 시각적 가이드).

모델 차원 크기 및 기타 하이퍼파라미터 측면에서는 다음과 같습니다.
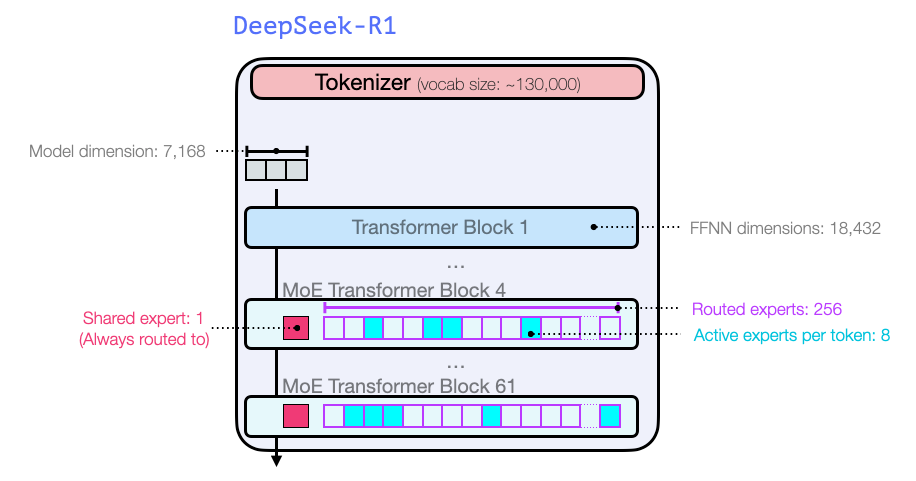
모델 아키텍처에 대한 자세한 내용은 이전 논문 두 개에 나와 있습니다.
결론
이제 DeepSeek-R1 모델을 이해할 수 있는 주요 직관이 생겼을 것입니다.
이 게시물을 이해하는 데 더 기본적인 정보가 필요하다고 생각되면 Hands-On Large Language Models 사본을 구입하거나 O'Reilly에서 온라인으로 읽고 Github에서 확인하는 것이 좋습니다.
Other suggested resources are:
- DeepSeek R1's recipe to replicate o1 and the future of reasoning LMs by
- Nathan Lambert
- A Visual Guide to Mixture of Experts (MoE) by
- Maarten Grootendorst
- Sasha Rush’s YouTube video Speculations on Test-Time Scaling (o1)
- Yannis Kilcher’s DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (Paper Explained)
- Open R1 is the HuggingFace project to openly reproduce DeepSeek-R1
- Putting RL back in RLHF

'개발자 > 인공지능과 인간' 카테고리의 다른 글
| AI에서 멀티모달이란 무엇일까? (5) | 2025.03.07 |
|---|---|
| 메타페어와 @bcbl_ 연구진의 연구 논문 - 브레인 투 텍스트 디코딩: 타이핑을 통한 비침습적 접근 방식 (0) | 2025.03.04 |
| AI로 인간의 사고 능력 저하 유발 (0) | 2025.02.18 |
| LLM University LLM 기술 설명 자료 (1) | 2025.01.28 |
| 구들 에이전트 백서 Google Agents Whitepapers (0) | 2025.01.27 |
| Richard Sutton 리처드 서튼 교수가 말하는 AI와의 공존 (2) | 2025.01.26 |
| 딥시크(DeepSeek)가 OpenAI와 Nvidia를 망하게 할까? (2) | 2025.01.25 |
| 자율형 인공지능 에이전트의 특징 (0) | 2025.01.24 |
더욱 좋은 정보를 제공하겠습니다.~ ^^



