라즈베리파이 Python Programming 08: List와 Byte array
이전 튜토리얼에서 기본적인 문법과 파이썬의 언어의 여러 요소에 대해 배웠습니다. Python은 문자열, 바이트, 바이트 배열, 범위, 튜플 및 목록의 6가지 유형의 시퀀스를 제공합니다.
중요하게도, 문자열, 바이트, 범위 및 튜플은 일단 정의되면 수정할 수 없는 변경 불가능한 시퀀스입니다. 이러한 시퀀스를 생성하거나 파괴하는 것만 가능합니다. 이렇게 하면 목록과 바이트 배열이 유일하게 변경 가능한 시퀀스로 남습니다.
Python은 또한 집합, 고정 집합 및 사전과 같은 정렬되지 않은 컬렉션을 지원합니다. 고정 세트는 변경할 수 없으며 세트와 사전은 변경 가능한 컬렉션입니다. 또한 사용자 정의 데이터 구조는 클래스로 정의할 수 있으며 항상 변경 가능합니다.
불변 시퀀스와 컬렉션은 코드 전체에서 특정 데이터 값을 사용해야 하는 경우에 유용합니다. 가변 시퀀스 및 컬렉션은 특정 이유로 그룹화할 수 있는 관련 데이터 값을 유지 관리하는 데 유용합니다. 변경 가능한 시퀀스/컬렉션의 데이터 값은 코드의 어디에서나 수정할 수 있으므로 조작 및 데이터 처리에 이상적으로 사용됩니다. 결국 우리는 어떤 프로그램에서든 데이터 값을 조작하고 처리합니다.
일반적으로 대부분의 응용 프로그램에서 데이터 값의 시퀀스 또는 (순서 없는) 컬렉션을 사용합니다. 따라서 이러한 변경 가능한 시퀀스/컬렉션의 데이터 값을 수정하고 조작할 수 있는 방법을 이해하는 것이 중요합니다. 목록, 바이트 배열, 집합 및 사전은 변경 가능한 Python 시퀀스/컬렉션으로 사용할 수 있습니다. 하나하나 검토해 보겠습니다.
List
목록은 변경 가능한 정렬된 항목 모음입니다. 목록의 항목은 임의적이며 모든 유형이 될 수 있습니다. 목록은 list() 생성자 또는 한 쌍의 대괄호([])를 사용하여 정의됩니다.
목록의 항목을 추가, 제거 및 수정할 수도 있습니다. 이러한 항목은 정수 키 또는 인덱스를 통해 액세스 할 수 있습니다. 목록에 있는 항목의 키 또는 인덱스는 0부터 시작합니다. 따라서 첫 번째 항목은 키 또는 인덱스 0을 갖습니다. 즉, "x"가 목록이면 해당 항목은 x [y]로 액세스 할 수 있습니다. 여기서 y는 액세스 되는 항목의 키/인덱스입니다. 음수 인덱스를 사용하면 목록의 시작이 아닌 끝에서 항목에 액세스 합니다.
목록의 끝에서 인덱스는 -1부터 시작합니다.
예를 들어:
리스트명 = [요소1, 요소2, 요소3, ...]
>>> a = []
>>> b = [1, 2, 3]
>>> c = ['Life', 'is', 'too', 'short']
>>> d = [1, 2, 'Life', 'is']
>>> e = [1, 2, ['Life', 'is']]
목록에 있는 하나 이상의 항목을 개별적으로 또는 조각을 통해 수정할 수 있습니다. 개별적으로 이렇게 하려면 다음과 같이 할당 또는 증강 할당의 대상 참조로 목록 항목에 액세스 합니다.
X = [1, 2, 3, 4]
X[1] = ‘a’ # x = [1, ‘a’, 3, 4]
X[2] += 22 # x = [1, a, 25, 4]
List 항목을 수정하기 위해 증강 할당을 사용할 때 RHS 표현식의 데이터 유형은 항목과 동일해야 합니다. 그렇지 않으면 결과는 의미 오류입니다.
다음과 같은 대입문의 대상 참조로 슬라이싱 연산자를 사용하여 List의 여러 항목을 함께 수정할 수도 있습니다.
X = [1, 2, 3, 4]
X[1:3] = [22, 33] # x = [1, 22, 33, 4]
슬라이스 x[a:b]는 목록 "x"에서 인덱스가 b-1 사이인 모든 항목을 수정하지만 "b"는 수정하지 않습니다. 슬라이스는 모든 iterable에 할당할 수 있습니다. 슬라이스보다 항목 수가 적은 iterable에 슬라이스가 할당되면 할당되지 않은 상태로 남아 있는 항목이 목록에서 제거됩니다. 슬라이스가 슬라이스보다 더 많은 항목을 포함하는 iterable에 할당되면 추가 항목이 슬라이스의 마지막 항목 뒤에 추가됩니다.
다음은 예입니다.
X = [1, 2, 3, 4]
X[1:3] = [22] # x = [1, 22, 4]
X = [1, 2, 3, 4]
X[1:3] = [22, 33, 44] # x = [1, 22, 33, 44, 4]
빈 슬라이스 x[a:a]에 특정 데이터 값/객체가 할당되면 해당 값/객체는 목록 "x"에서 인덱스 "a:"가 있는 항목 앞에 추가됩니다. 마찬가지로 슬라이스는 목록 "x"에 대한 대상 참조로 x[:] 표현식을 사용하여 전체 목록을 덮고 새 값/객체를 해당 목록에 다시 바인딩할 수 있습니다.
다음 예를 고려하십시오.
X = [1, 2, 3, 4]
X[1:1] = [22] # x = [1, 22, 2, 3, 4]
X = [1, 2, 3, 4]
X[:] = [22, 33, 44] # x = [22, 33, 44]
"del" 문을 사용하여 모든 항목 또는 항목 조각을 목록에서 삭제할 수 있습니다. 여기서 슬라이싱 연산자는 보폭을 사용하여 일정한 간격으로 항목 삭제를 건너뛸 수도 있습니다.
다음은 몇 가지 예입니다.
X = [1, 2, 3, 4, 5, 6, 7, 8, 9]
del X[8] # x = [1, 2, 3, 4, 5, 6, 7, 8]
del X[4:6] # x = [1, 2, 3, 4, 7, 8]
del X[4:] # x = [1, 2, 3, 4]
del X[::2] # x = [2, 4]
List에는 다음과 같은 메서드가 있습니다.

# insert() : 리스트의 특정 위치에 요소 삽입
>>> test1 = [1,2,3]
>>> test1.insert(1, 10) # 두 번째위치에 10 삽입
>>> test1
[1, 10, 2, 3]
# append() : 리스트 끝에 요소 삽입
>>> test1 = [1,2,3]
>>> test1.append(5)
>>> test1
[1, 2, 3, 5]
# clear() : 리스트 내용 모두 삭제
>>> test1 = [1,2,3]
>>> test1.clear()
>>> test1
[]
# del() : 리스트의 특정 위치 요소 삭제
>>> test1 = [1,2,3]
>>> del(test1[1])
>>> test1
[1, 3]
# remove() : 리스트의 특정 요소 삭제
>>> test1 = [1,2,3]
>>> test1.remove(2)
>>> test1
[1, 3]
# pop() : 리스트의 마지막 요소 출력 후 삭제
>>> test1 = [1,2,3]
>>> test1.pop()
3
>>> test1
[1, 2]
# len() : 리스트 요소의 개수
>>> test1 = [1,2,3]
>>> len(test1)
3
# count() : 리스트 내 특정 요소의 개수
>>> test1 = [1,2,3,1,2]
>>> test1.count(1)
2
>>> test1.count(3)
1
# copy : 리스트 복사
>>> test1 = [1,2,3]
>>> test2 = test1.copy()
>>> test2
[1, 2, 3]
# extend() : 리스트 병합 (+연산과 같은 효과)
>>> test1 = [1,2,3]
>>> test2 = [7,8,9]
>>> test1.extend(test2)
>>> test1
[1, 2, 3, 7, 8, 9]
# split() : 리스트 분리
>>> 'aaron@tistory'.split('@')
['aaron', 'tistory']
>>> 'aaron@tistory'.split('@')[0]
'aaron'
# index() : 리스트의 특정 요소 검색
>>> test1 = [1,2,3]
>>> test1.index(3)
2 # 요소의 위치 리턴
>>> test1.index(4)
ValueError: 4 is not in list # 일치하는 요소가 없으면 에러를 리턴해서 잘 사용되지 않음
# sort() : 정렬
>>> test1 = [8,1,7,2,6,3,10,4,9,5]
>>> test1.sort() # default 오름차순 정렬
>>> test1
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> test1 = [8,1,7,2,6,3,10,4,9,5]
>>> test1.sort(reverse = True) # 내림차순 정렬
>>> test1
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
# sorted() : 정렬된 리스트를 새로운 리스트에 복사
>>> test1 = [8,1,7,2,6,3,10,4,9,5]
>>> test2 = sorted(test1)
>>> test2
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# reverse() : 리스트 역순 출력
>>> test1 = [8,1,7,2,6,3,10,4,9,5]
>>> test1.reverse()
>>> test1
[5, 9, 4, 10, 3, 6, 2, 7, 1, 8]
이러한 메서드는 list_name.method_name 구문을 사용하여 목록에 적용할 수 있습니다. 다음은 예입니다.
x = [‘lion’, ‘tiger’]=
x.append(‘elephant’) # x = [‘lion’, ‘tiger’, ‘elephant’]
x.insert[0, ‘leopard’] # x = [‘leopard’, ‘tiger’, ‘elephant’]
x.extend([‘cat’, ‘snake’]) # x = [‘leopard’, ‘tiger’, ‘elephant’, ‘cat’, ‘snake’]
x.remove[‘snake’] # x = [‘leopard’, ‘tiger’, ‘elephant’, ‘cat’]
x.pop(0) # x = [‘tiger’, ‘elephant’, ‘cat’]
x.index(‘cat’) # returns 2
y = x.copy() # y = [‘tiger’, ‘elephant’, ‘cat’]
x.count(‘cat’) # returns 1
x.count(‘lion’) # returns 0
x.sort() # x = [‘cat’, ‘elephant’, ‘tiger’]
def f(e):
return len(e)
x.sort(key = f) # x = [‘cat’, ‘tiger’, ‘elephant’]
x.reverse() # x = [‘elephant’, tiger, ‘cat’]
x.clear() # x = []
다음 내장 함수는 List를 인수로 받아들입니다.

목록은 해당 목록의 크기를 가져오기 위해 len() 함수에 인수로 전달할 수 있습니다. 다음은 예입니다.
x = [1, 2, 3, 4]
len(x) #returns 4
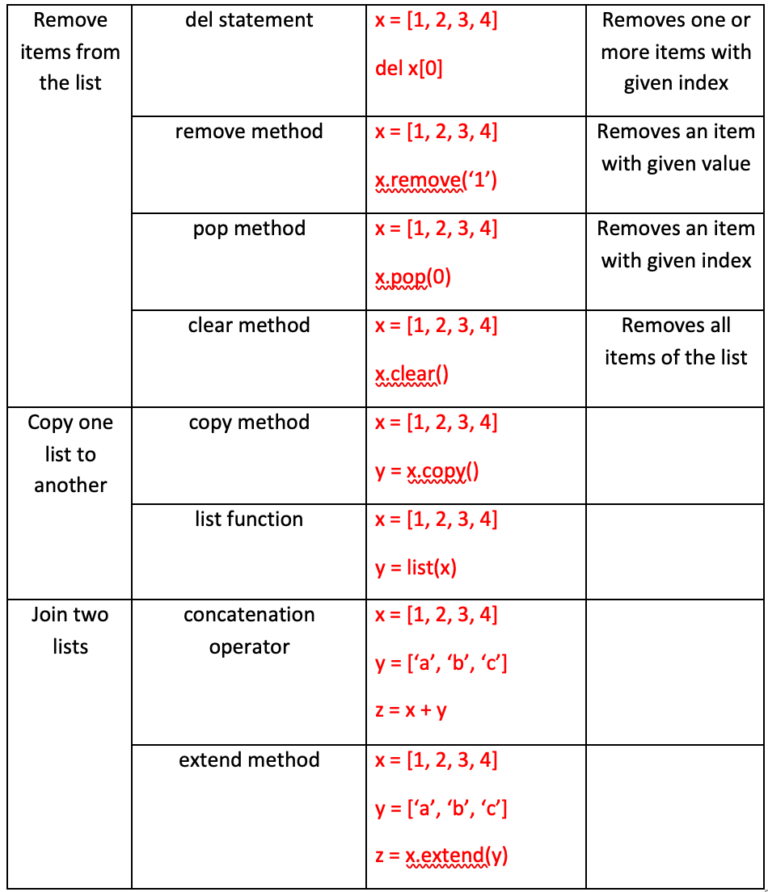
다음 표에는 연산자, 명령문, 메서드 또는 함수를 사용하는 목록의 일반적인 작업이 요약되어 있습니다.

문자열, 바이트 및 바이트 배열
문자열은 유니코드(Python V3) 또는 ASCII 문자(Python V2)의 변경할 수 없는 시퀀스입니다. 바이트는 변경할 수 없는 바이트 시퀀스입니다. 바이트 배열은 변경 가능한 바이트 시퀀스입니다.
문자열은 유니코드/ASCII 문자의 작은따옴표, 큰따옴표 또는 삼중 따옴표 시퀀스로 정의됩니다. 문자열로 사용하려는 iterable의 모든 항목에는 따옴표가 있어야 합니다. 그렇지 않으면 파이썬은 그것을 식별자로 취급하고 참조라고 가정합니다.
다음은 예입니다.
x = [‘a’, ‘b’, ‘c’]
a = 12
b = 10
c = 11
y = [a, b, c]
print(x) # Prints [‘a’, ‘b’, ‘c’]
print(y) # Prints [12, 10, 11]
문자열은 변경할 수 없는 시퀀스입니다. 즉, 인덱스에 액세스 하여 문자열의 항목(유니코드/ASCII 문자)을 추가, 제거 또는 수정할 수 없습니다. 따라서 다음은 유효하지 않은 진술입니다.
x = “Python”
x[0] = “J” #INVALID
del x[0] #INVALID
그러나 빌드된 메서드, 함수 및 사용자 정의 함수를 사용하여 문자열 조작을 수행할 수 있습니다. 문자열 객체의 유사 문자는 replace() 함수를 사용하여 바꿀 수 있습니다.
이 예를 확인하십시오.
x = ‘PPython’
x = x.replace(“P”, “J”)
print(x)
바이트는 byte() 함수로 정의하거나 바이트 문자열 앞에 "b"를 접두사로 지정합니다. 바이트도 변경할 수 없는 시퀀스입니다. 인덱스에서 액세스하여 바이트 개체의 바이트를 추가, 제거 또는 수정할 수 없습니다. 다음은 바이트 개체의 유효한 예입니다.
x = b“Python”
x = byte(“Python”)
바이트 배열은 바이트의 변경 가능한 버전입니다. bytearray() 함수를 사용하여 정의할 수 있습니다. 바이트 및 바이트 배열의 유효한 예는 다음과 같습니다.
x = bytearray(“Python”, ‘utf-8’) #string defined as byte array
x = bytearray(b“Python”)
x = bytearray([1, 2, 3, 4, 5,])
x = bytearray() # Empty bytearray
bytearray() 함수를 사용하여 문자열을 바이트 배열로 정의하는 경우 문자열을 따옴표로 묶고 인코딩을 인수로 전달해야 합니다. 바이트와 달리 바이트 배열은 변경 가능합니다. 즉, 인덱스를 통해 액세스 하여 바이트 배열의 항목(바이트)을 추가, 제거 또는 수정할 수 있습니다.
그러나 바이트 배열의 항목은 슬라이싱 연산자를 통해서만 액세스 할 수 있습니다. 다음은 바이트 배열을 수정하는 잘못된 예입니다.
x = bytearray(b”Python”)
print(x)
x[0] = b”J” #INVALID
print(x)
다음은 바이트 배열을 수정하는 유효한 예입니다.
x = bytearray(b”Python”)
print(x) #returns bytearray(b‘Python’)
x[0:1] = b”J”
print(x) #returns bytearray(b‘Jython’)
다음 예는 바이트 배열에서 바이트 추가, 제거, 수정 및 추가를 보여줍니다.
x = bytearray(b”Python”)
print(x)
x[6:] = b” is fun” #adding items to byte array by assignment
print(x) #prints bytearray(b’Python is fun’)
x.append(110) #appending items to byte array
x.append(121)
print(x) #prints bytearray(b’Python is funny’)
x[6:] = b”” #removing items in byte array by assignment
print(x) #prints bytearray(b’Python is funny’)
x[6:] = b” Objects”
print(x) #prints bytearray(b’Python Objects’)
del x[6:] #removing items in byte array by del statement
print(x) #prints bytearray(b’Python’)
Raspberry Pi에서 이러한 모든 예제 코드를 테스트해야 합니다.
다음 튜토리얼에서는 Set와 Dictionary에 데이터 값을 조작하는 방법을 알아보겠습니다.

'개발자 > 라즈베리파이4' 카테고리의 다른 글
| 라즈베리파이 4 Adafruit DHT11 DHT22 온도 습도 센서 문제 (0) | 2021.11.11 |
|---|---|
| 라즈베리파이 4에서 VNC 접속하여 사용하기 Raspberry Pi4 VNC Connect (2) | 2021.11.10 |
| 라즈베리파이 Python Programming 10: 객체 지향 Python (0) | 2021.11.05 |
| 라즈베리파이 Python Programming 09: 파이선 set and dictionary (0) | 2021.11.04 |
| 라즈베리파이 Python Programming 07: 파이선 기초 2/2 (0) | 2021.11.02 |
| 라즈베리파이 Python Programming 06: 파이선 기초 1/2 (0) | 2021.11.01 |
| 라즈베리파이 파이선 프로그래밍 05: Python 소개 (0) | 2021.10.29 |
| 라즈베리파이 파이선 프로그래밍 04. Raspberry Pi 초기 설정 (1) | 2021.10.28 |
더욱 좋은 정보를 제공하겠습니다.~ ^^



