라즈베리파이 하둡 클러스터 가이드
이 가이드에서는 세 대의 Raspberry Pi에서 실행되는 Hadoop 클러스터를 설정하는 방법을 살펴봅니다.

아파치 하둡은 여러 컴퓨터 간의 통신을 용이하게 하는 오픈 소스 소프트웨어입니다. 이러한 기능을 통해 대량의 데이터를 저장하고 처리할 수 있습니다. Hadoop은 내결함성이 뛰어나고 상용 하드웨어에서 실행할 수 있기 때문에 전통적으로 클러스터는 상대적으로 저렴하고 더 많은 공간과 처리 능력을 위해 쉽게 확장할 수 있었습니다. 이러한 기능 덕분에 도입률이 크게 증가했으며, 이 프레임워크는 00년대 후반 빅데이터의 출현을 이끈 촉매제 중 하나였습니다.
시작하기에 앞서, 2020년에 왜 누군가가 하둡 클러스터를 구축할까요? 몇 가지 이유가 있습니다:
- 하둡의 전반적인 영향력은 감소하고 있지만, 하둡의 작동 방식을 이해하는 것은 Spark, Kafka, Kubernetes 등과 같은 보다 관련성이 높은 빅데이터 구성 요소의 기초 및 비교 지점이 될 수 있습니다.
- Hadoop 클러스터를 구축하면 터미널, 보안 셸, 네트워킹 사용 등 유용한 일반 컴퓨팅 개념을 배울 수 있습니다.
- 클러스터의 하드웨어는 다른 프로젝트의 지속적인 학습과 개발을 위해 용도를 변경할 수 있습니다.
- 정말 재미있어요!

하드웨어 구성 부품:
- 라즈베리 파이 B+ 3개 £99.78
- 마이크로 SD 카드 32GB 3개 £17.07
- USB C - USB 2.0 케이블 3개(5개 팩) £7.99
- 6포트 USB 충전기 £17.49
- 5포트 이더넷 스위치 £6.78
- USB 2.0 - 이더넷 케이블 어댑터 £10.99
- 이더넷 케이블 4개 £13.96
- USB 2.0 - 1.35mm DC 5V 어댑터 £5.99
- 아크릴 케이스 £16.59
- 양면 스티커 테이프 £5.99
합계: £202.63

단계별 가이드
이 특정 가이드는 MacBook 머신을 사용하는 "헤드리스" 라즈베리 파이 설정을 위한 것입니다. 즉, 파이에는 자체 전용 화면과 키보드가 없고 대신 MacBook(이 가이드에서는 간단히 머신이라고 함)을 사용하여 제어합니다.
1. 라즈비안 OS 이미지를 SD 카드에 플래시합니다.
먼저 Pis용 운영체제(OS)를 다운로드합니다. 다양한 선택지가 있지만 저는 데스크톱과 함께 제공되는 공식 라즈베리파이 OS인 Raspbian과 권장 소프트웨어(여기에서 다운로드)를 사용하고 있습니다. 가볍고 사용하기 쉬우며 Pi 하드웨어에 최적화되어 있어 Pi 재단에서 선호하는 OS로 추천하고 있습니다. 다운로드가 완료되고 압축이 풀리면 컴퓨터에 확장자가 .img인 파일이 하나 생깁니다.
그 다음에는 SD 카드에 OS 이미지를 써야 합니다. 이를 위해 저는 벨레나에처 플래싱 소프트웨어를 다운로드하여 사용했습니다(여기에서 다운로드). 사용하기 매우 직관적입니다. SD 카드를 기기에 삽입하고 belenaEtcher를 연 다음 플래시할 .img 파일을 선택하기만 하면 됩니다.
동일한 OS 이미지를 사용하여 나머지 두 개의 SD 카드에 대해 플래싱을 반복합니다.
2. 하드웨어 설정하기
이것은 간단합니다. Pis를 아크릴 케이스에 장착하고 충전기와 라우터에 테이프를 붙인 다음 전선을 연결합니다.
3. 개별 Pis에 SSH로 로그인하고 파일 시스템을 확장합니다.
플래싱이 완료되면 부팅 SD 카드가 자동으로 꺼집니다. 카드를 다시 머신에 삽입하고 터미널에서 /Volumes/boot/ssh를 입력합니다.
컴퓨터에서 SD 부팅 카드를 꺼내서 Pi에 삽입한 다음, Pi를 컴퓨터와 전원에 연결합니다.
이제 Pi의 IP 주소를 찾아야 합니다. 터미널에 ping raspberrypi.local을 입력하면 이 작업을 수행할 수 있습니다(핑을 중지하려면 ctrl + z를 누르세요).
핑을 통해 얻은 정보를 사용하여 IP 주소를 확인한 후 ssh pi@169.254.63.20(IP 주소가 달라질 수 있음)를 입력합니다. 계속 연결할 것인지 묻는 메시지가 표시되면 예를 입력합니다. 그런 다음 비밀번호를 입력하라는 메시지가 표시됩니다. Pi의 기본 비밀번호는 라즈베리입니다.
Pi에 성공적으로 SSH에 접속했으면 sudo raspi-config를 입력합니다. 그러면 구성 도구로 이동합니다. 7가지 고급 옵션으로 이동하여 A1 파일 시스템 확장을 선택합니다. 완료로 이동하고 메시지가 표시되면 재부팅합니다.
다른 두 개의 Pis에 대해 이 단계를 반복합니다.
참고: 쉽게 제어할 수 있도록 Pis에 그래픽 사용자 인터페이스(GUI)를 설정하는 것도 고려해 볼 수 있습니다. 이 비디오 가이드를 따라 설정할 수 있습니다.
4. 네트워크, 사용자 및 SSH 키를 구성합니다.
마지막 Pi의 파일 시스템을 확장한 후에는 다시 SSH로 접속하지 마세요. 대신 머신의 터미널에 sudo nano /etc/hosts를 입력합니다. 문서 하단으로 이동하여 아래 내용을 추가한 후 Ctrl + X를 눌러 파일을 저장합니다(IP 주소는 사용자마다 다를 수 있음):
169.254.24.25 master
169.254.25.188 worker1
169.254.63.20 worker2
이제 IP 주소를 사용하는 대신 ssh pi@master를 사용하여 마스터 파이에 SSH로 로그인할 수 있습니다(다른 두 파이의 경우 마스터를 worker1 또는 worker2로 바꾸세요). 이 방법을 시도해보고 연결되면 이전에 사용한 sudo nano /etc/hosts 명령을 입력하여 Pi의 호스트 파일을 아래와 같이 추가합니다(오류를 방지하기 위해 raspberrypi를 127.0.1.1로 대체하는 것이 좋습니다):
127.0.1.1 master # worker1, worker2 for the other two Pis
169.254.24.25 master
169.254.25.188 worker1
169.254.63.20 worker2
다음 단계는 Pis의 호스트 이름을 바꾸는 것입니다. 이렇게 하려면 연결된 상태에서 sudo nano /etc/hostname을 입력하고 각 Pi에 대해 raspberrypi를 각각 master, worker1 및 worker2로 바꿉니다.
각 Pi에 대해 아래 명령을 입력하여 전용 Hadoop 그룹과 사용자를 생성합니다(비밀번호를 설정해야 하지만 나머지 필드는 비워 두어도 됩니다):
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
sudo adduser hduser sudo
마지막 단계는 SSH 키를 생성하는 것입니다. 이렇게 하면 클러스터가 형성될 때 Pis가 서로 원활하게 통신할 수 있습니다. 각 Pis에 대해 아래 단계를 반복하고 그에 따라 복사할 때 Pis의 이름을 바꿉니다.
ssh-keygen -t ed25519 # 다른 알고리즘을 자유롭게 사용할 수 있습니다.
ssh-keygen -t ed25519 # You are free to use another algorithm
ssh-copy-id hduser@master
ssh-copy-id hduser@worker1
ssh-copy-id hduser@worker2
5. Hadoop 폴더 구조 및 환경 변수 만들기
아래 명령어를 사용하여 필요한 HDFS(Hadoop 분산 파일 시스템) 폴더 구조를 생성합니다:
sudo mkdir /opt/hadoop_tmp/
sudo mkdir /opt/hadoop_tmp/hdfs
sudo mkdir /opt/hadoop_tmp/hdfs/namenode # master only
sudo mkdir /opt/hadoop_tmp/hdfs/datanode # Both workers only
계속하기 전에 사용자 권한을 수정해야 합니다. 이렇게 하면 Hadoop이 필요한 폴더를 수정할 수 있습니다(클러스터를 구축할 때 이 문제로 가장 큰 어려움을 겪었고 오류를 발견하기 위해 Hadoop 로그를 검토해야 했습니다).
sudo chown hduser:hadoop -R /opt/hadoop
sudo chown hduser:hadoop -R /opt/hadoop_tmp
sudo chown hduser:hadoop -R /opt/hadoop_tmp/hdfs/datanode
마지막으로 nano ~/.bashrc를 입력하고 파일 하단에 아래 줄을 추가하여 Bash 프로필에 Java 및 Hadoop 환경 변수를 추가해야 합니다(프로필을 변경한 후 프로필 유형 소스 ~/.bashrc를 저장하여 프로필을 새로 고친 후):
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")
export HADOOP_HOME=/opt/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export PATH=$PATH:$HADOOP_INSTALL/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
6. Hadoop 다운로드, 설치 및 구성
실행할 Hadoop 버전을 선택해야 합니다(여기에서 다운로드). 이 프로젝트에서는 Hadoop-3.2.1을 실행합니다. 다운로드가 완료되면 터미널을 사용하여 다운로드한 .tar.gz 파일이 들어 있는 폴더로 이동합니다. scp hadoop-3.2.1.tar.gz hduser@master:/opt/를 실행합니다. 이렇게 하면 Hadoop 파일이 마스터 파이에 복사됩니다. 두 개의 워커에 대해서도 이 과정을 반복합니다.
파이에 SSH로 접속하여 각각에 아래 명령을 실행합니다. 이렇게 하면 더 이상 필요하지 않은 Hadoop tarball의 압축이 풀리고 폴더 이름이 바뀌며 마지막으로 .tar.gz 파일 자체가 삭제됩니다.
sudo tar -xvzf /opt/hadoop-3.2.1.tar.gz -C /opt/
mv /opt/hadoop-3.2.1 /opt/hadoop
rm /opt/hadoop-3.2.1.tar.gz
마스터 파이에서는 nano /opt/hadoop/etc/hadoop/workers만 실행하고 기존 텍스트를 별도의 줄에서 worker1 및 worker2로 바꿉니다.
아래를 입력하여 4개의 Hadoop .xml 파일을 편집합니다:
nano /opt/hadoop/etc/hadoop/core-site.xml
# Configuration to be added:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>fs.default.FS</name>
<value>hdfs://master:9000/</value>
</property>
</configuration>
nano /opt/hadoop/etc/hadoop/hdfs-site.xml
# Configuration to be added:
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop_tmp/hdfs/datanode</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop_tmp/hdfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value> # Based on the number of workers you have
</property>
</configuration>
nano /opt/hadoop/etc/hadoop/yarn-site.xml
# Configuration to be added:
<configuration>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
</configuration>
nano /opt/hadoop/etc/hadoop/mapred-site.xml
# Configuration to be added:
<configuration>
<property>
<name>mapreduce.job.tracker</name>
<value>master:5431</value>
</property>
<property>
<name>mapred.framework.name</name>
<value>yarn</value>
</property>
</configuration>
마지막으로, nano /opt/hadoop/etc/hadoop/hadoop-env.sh를 입력하고 주석 처리된 Java 경로 줄을 export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")로 대체하여 Hadoop에 환경 변수를 추가해야 합니다. 참고: 첫 번째 Java 경로 줄(예: JAVA_HOME=/usr/java/testing hdfs dfs -ls)은 바꾸지 마세요.
7. 클러스터 포맷 및 테스트
마지막으로 해야 할 일은 네임노드, 파일 시스템을 포맷하고 디렉터리를 초기화하는 것입니다. 이 모든 작업은 마스터 파이에서 간단한 명령어인 hdfs namenode -format으로 수행할 수 있습니다.
이제 Hadoop Raspberry Pi 클러스터가 작동할 준비가 되었습니다. 테스트하려면 /opt/hadoop/sbin/start-dfs.sh를 사용하여 Hadoop 분산 파일 시스템 데몬을 시작하고 /opt/hadoop/sbin/start-yarn.sh를 사용하여 Yarn을 시작하세요.

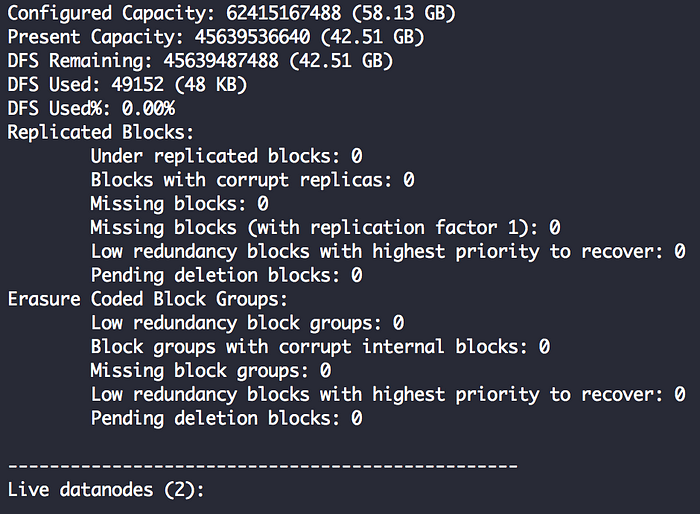
마지막 단계에서 문제가 없었다고 가정하고 ./bin/hdfs dfsadmin -report를 입력하여 클러스터의 상태를 확인할 수 있습니다(라이브 데이터 노드 수를 관찰합니다).
다음 단계는 무엇인가요?
다음 단계는 클러스터를 실행하기 위한 간단한 MapReduce 프로그램을 작성하는 것입니다. 그 후에는 Spark나 Hue와 같은 Hadoop 에코시스템의 추가 구성 요소를 설치하여 클러스터를 개선하는 것입니다.
이 클러스터의 컴퓨팅 및 스토리지 유틸리티는 2020년의 저예산 노트북과도 경쟁할 수 없지만, 지난 10년간 Google과 Facebook과 같은 회사를 지원해온 대부분의 물리적 및 소프트웨어 구성 요소를 포함하고 있습니다. 전반적으로 라즈베리파이 하둡 클러스터 구축은 매우 즐겁고 매력적인 교육 경험입니다.
영감을 준 제이슨 카터(Jason I. Carter), 올리버 후, 알란 버두고(Alan Verdugo)의 가이드에 특별히 감사의 말씀을 전합니다.
다른 참고 사이트
Setting up a Raspberry Pi Hadoop Cluster
라즈베리파이 yarn 클러스터에 하둡(hadoop)과 스파크(spark) 설치하기
Big Data – Cluster Environment: Powered by Raspberry Pi-4, Hadoop, and Spark
Installing Hadoop HDFS data lake in Raspberry Pi 4 Ubuntu cluster